출처 : http://blog.naver.com/seuis398?Redirect=Log&logNo=70078268543
euckr은 한글을 표현하는 방법의 하나로서, 현재 많은 어플리케이션에서 사용중이며, Windows 운영체제도 euckr을 확장한 cp949 인코딩을 사용하고 있다. euckr 인코딩 방식은 ascii 문자셋과 ksx1001 문자셋을 처리할 수 있다.
ksx1001 문자셋에는 특수문자, 한글, 한자를 2byte 코드로 표현하고 있으며, 0xA1A1 부터 0xFEFE 사이의 코드를 사용하고 있다.
흔히 한글 문자셋은 ksc5601이라는 이름으로 알려져 있는데, ksc5601 문자셋은 ksx1001 문자셋 표준의 이전 이름이며, 1997년 ksx1001으로 명칭이 변경되었다. ksx1001 문자셋은 1998년, 2002년 두차례 업데이트 되었으므로, euckr 인코딩에서 사용하는 한글 문자셋을 ksc5601이라고 부르는 것은 맞지 않다.

아쉽게도 ksx1001은 자음과 모음으로 조합가능한 모든 한글을 표현하지 못한다.
ksx1001은 자음과 모음의 조합으로 만들어진 2350자의 한글을 각자의 코드로 표현한다.
이른바 완성형 코드이다.
(예) 가 : 0xB0A1 / 늪 : 0xB4CB
전체 코드 테이블은 국가표준종합정보센터(http://www.standard.go.kr/)에서 검색 가능하다.
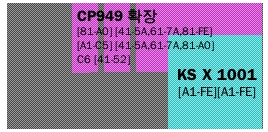
euckr을 보완하기 위하여 Microsoft는 cp949(ms949)를 정의하였다.
cp949는 ksx1001-1998 버전의 문자셋을 기반으로 8822자의 한글 조합을 추가한 문자셋이다.
현재 Windows 플랫폼에서 한국어(euckr)이라고 사용하는 것은 euckr이 아닌 cp949이다.
(그리고 참고로 Windows 플랫폼에서 유니코드라고 사용하는 것은 실제 유니코드가 아닌 utf8이다.)
간단하게 cp949의 코드에서 추가된 영역을 표로 나타내면 아래와 같다.